Issue
- After deployment, instances intermittently failed to start normally
- Investigation showed the health check interval was too short at 1 minute, causing intermittent failures during initial startup
Analysis
In the logs, I found a pattern of repeated restarts occurring anywhere from a few minutes to as long as every 30 minutes.
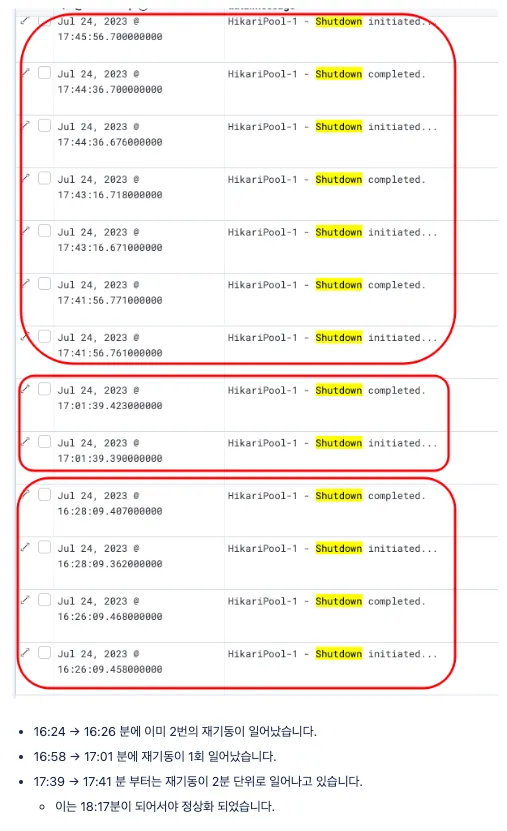
Logs showing the repeated pod restart pattern after deployment.
Checking with DevOps, the k8s pod’s health check interval was 1 minute, and the structure automatically restarted the pod if application startup took longer than 1 minute. Increasing the health check to 2 minutes was a temporary fix, but the root cause remained.

Analysis of the 8/6 recurrence tied to the 1-minute health check interval.
Improvement
I resolved it by separating the responsibilities of startup-time and runtime state checks.
- Adjusted the startupProbe to grant a longer grace period only during initial startup
- Kept the livenessProbe, which checks subsequent state, unchanged
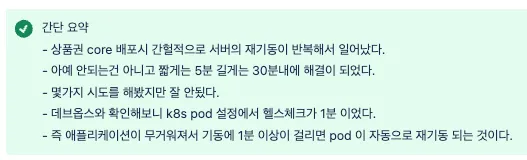
Brief summary: a slow, heavy startup exceeding the 1-minute health check caused repeated pod restarts.